Translated from Machine Learning Interviews – Machine Learning Systems Design by Chip Huyen
Vì đây là một bài viết rất hay nên mình quyết định dịch lại để nó có thể đến với nhiều độc giả hơn. Để xem phiên bản mới nhất, các bạn nên truy cập Github của bạn Huyền. Cũng khoảng 12 tháng rồi repo ấy chưa cập nhật, nếu mà có thêm contributors từ network của Huyền thì tốt quá, vì họ đều rất giỏi. Cảm ơn bạn Huyền nhiều <3 (bằng tuổi).
- Introduction – Giới thiệu:
Phần này bao gồm 27 câu hỏi mở để kiểm tra khả năng của bạn trong việc giải quyết các vấn đề thực tế. Nhà phỏng vấn sẽ đưa cho bạn một vấn đề, có thể liên quan tới sản phẩm của họ và yêu cầu bạn thiết kế một hệ thống ML để giải quyết nó. Những câu hỏi phỏng vấn như thế này vô cùng phổ biến và thường thì bạn sẽ được hỏi ít nhất là một câu trong quá trình phỏng vấn. Trong một giờ đồng hồ, bạn sẽ có thời gian để xử lý một hoặc hai câu như vậy.
Những câu hỏi này thường có nhiều hơn một đáp án, vì có nhiều cách để giải quyết một vấn đề cũng như nhiều câu hỏi mở rộng mà nhà phỏng vấn có thể đặt ra để đánh giá kiến thức của ứng viên, khả năng triển khai và tư duy phản biện . Nhà phỏng vấn thường cho rằng, kể cả khi bạn không thể đưa ra một giải pháp hữu hiệu, nhưng nếu bạn có thể cho họ thấy được rằng bạn hiểu những ràng buộc, trade-off, và cân nhắc trong việc thiết kế hệ thống – thì cũng khá ổn rồi. (Lưu ý: constraints, trade-off, concerns: 3 cái này ở phía dưới các bạn sẽ gặp và biết đó là cái gì nhé – mình sẽ giữ nguyên một số từ tiếng Anh – vì dịch sang tiếng Việt nó hơi gượng và không truyền tải hết ý nghĩa được).
Những câu hỏi như vậy khiến các bạn ứng viên vừa yêu vừa ghét. Yêu là bởi chúng thực tế, linh động, và ít yêu cầu học thuộc (Lưu ý, đoạn này nguyên tác là “require the least amount of memoization”, tuy nhiên memoization lại có nghĩa khác – nên mình đoán là tác giả thực chất muốn viết là memorization). Đồng thời các ứng viên cũng ghét những câu hỏi như vậy bởi vô số lý do. Thứ nhất là không có tiêu chuẩn để đánh giá câu trả lời, thế cho nên sẽ rất đuối nếu nhà tuyển dụng hỏi một câu hỏi mở mà lại mong đợi một đáp án vừa ý họ, sẽ rất khó để có được một đáp án chuẩn.
Thứ hai, những câu hỏi như vậy rất tối nghĩa và không có một khuôn mẫu nhất định cho những phỏng vấn như vậy. Mỗi câu hỏi bắt đầu bằng việc “hãy thiết kế X”, nhiệm vụ của bạn là phải hỏi lại nhà tuyển dụng để làm rõ, và khoanh vùng vấn đề lại. Tiếp đó, hãy dẫn dắt nhà tuyển dụng đến với cách giải quyết của bạn, và chọn lựa những điểm bạn sẽ tập trung vào. Việc làm này sẽ nói lên kinh nghiệm, sự hiểu biết, cũng như hứng thú của bạn đối với vấn đề đang cần được giải quyết. Rất nhiều ứng viên còn không rõ một câu trả lời hay là như thế nào, bởi vì những điều này không được dạy ở trường học. Nếu bạn chưa bao giờ triển khai một hệ thống ML thực tế, bạn có thể còn chẳng biết cần phải cân nhắc những gì khi thiết kế chúng. Khi tôi hỏi trên Twitter: “các nhà tuyển dụng tìm kiếm điều gì khi phỏng vấn những câu như vậy”, tôi nhận được nhiều đáp án khác nhau.
Dmitry Kislyuk, một kỹ sư trưởng về thị giác máy (Computer Vision) tại Pinterest hứng thú với những công đoạn không liên quan tới mô hình hóa (non-modeling parts):
“Hầu hết các ứng viên biết về các Model như Linear hay Decision Tree, hay LSTM etc., và ghi nhớ những thông tin cần thiết, thế cho nên với tôi thì những thứ thú vị hơn trong câu hỏi việc phỏng vấn là kiến thức về chuẩn bị dữ liệu, đánh giá mô hình, lưu trữ features (data cleaning, data preparation, logging, evaluation metrics,
scalable inference, feature stores (recommenders/rankers))”
Ravi Ganti, nhà khoa học dữ liệu tại WalmartLabs, tìm kiếm những ứng viên có khả năng “chia để trị” vấn đề: “Khi tôi hỏi những câu như vậy, thứ tôi cần biết là liệu rằng:
1. Ưng viên có thể chia nhỏ vấn đề ra thành những thành phần đơn giản hơn được không (building blocks)
2. Ứng viên có thể nhận diện những mục nào yêu cầu sự hỗ trợ của ML không”
Tương tự, Illia Polosukhin, đồng sáng lập khởi nghiệp NEAR Protocol và cũng là cựu nhân viên tại Google và MemSQL, muốn tìm kiếm ứng viên có khả năng xử lý những vấn đề có tính chất nền tảng (fundamental):
“Tôi nghĩ thiết kế hệ thống ML là một câu hỏi phỏng vấn quan trọng. Ứng viên có thể định nghĩa vấn đề, tìm các metrics (đo lường) phù hợp và Can a
person define the problem, identify relevant metrics, diễn giải từ dữ liệu và trích xuất những tính năng (feature) quan trọng, cũng như nắm rõ ML có thể làm được gì. Các phương pháp trong ML thay đổi hàng năm, nhưng việc giải quyết vấn đề thì vẫn vậy”
Quyển sách này không cung cấp những câu trả lời hoàn hảo, bởi chúng vốn không tồn tại. Thay vì vậy, nó nhắm tới việc cung cấp một phương thức (framework) để tiếp cận những câu hỏi đó
Research vs production
Trước tiên hãy tìm hiểu sự khác biệt giữa ML trong học thuật (academic) và trong thực tiễn (production). Ở môi trường học thuật, người ta quan tâm nhiều đến việc huấn luyện (training), còn trong môi trường thực tế thì họ quan tâm nhiều đến hiệu quả (phục vụ – serving) nhiều hơn. Các ứng viên học về ML nhưng chưa triển khai thực tế thường sẽ bị nhầm lần điều này, dẫn đến việc chọn nhầm vấn đề để giải quyết – tức là, cố gắng làm cho mô hình chạy thật tốt khi benchmark nhưng lại không cân nhắc nó sẽ được sử dụng ngoài đời thật như thế nào
Performance requirements (Yêu cầu về hiệu năng – thực ra chữ hiệu năng dịch ở đây không đúng, nó là đo lường dạng như độ chính xác – accuracy, hay F1 score thôi – mình sẽ sửa sau):
Trong nghiên cứu ML, có một sự ám ảnh không hề nhẹ với SOTA State-of-the-Art) – tức là những nghiên cứu mới và có hiệu năng cao hơn những nghiên cứu trước đó dựa vào một số benchmark nhất định. Để đạt được một chút xíu cải thiện trong performance, các nhà nghiên cứu thường dùng những kỹ thuật khiến cho mô hình quá phức tạp và trở nên không hiệu quả (trong production nhé)
Một kỹ thuật mà họ hay dùng (ví dụ để chiến thắng 1 triệu đô của Netflix) là Ensemble Learning: kết hợp nhiều mô hình-thuật toán khác nhau để cải thiện hiệu năng so với mô hình độc lập. Đúng là nó sẽ giúp bạn có được một mô hình hiệu quả hơn và performance (ví dụ độ chính xác accuracy), nhưng hệ thống sẽ trở nên phức tạp hơn, yêu cầu nhiều thời gian để train hơn và tốn kém nhiều hơn. Vài phần trăm chênh lệch là cực kỳ quan trọng trong một cuộc thi về ML, nhưng nó chả có nghĩa lý gì đối với người dùng (User)- họ không phân biệt được ứng dụng có độ chính xác 95% và ứng dụng chính xác 96% khác nhau chỗ nào cả.
Lưu ý: có rất nhiều ý kiến cho rằng các cuộc thi ML đua top Bảng Xếp Hạng, như Kaggle là không phải ML (tức là tính chất của nó không phải là ML thực sự, lý do bên dưới). Một lý lẽ hiển nhiên đó là Kaggle đã giúp bạn thực hiện rất nhiều bước quan trọng (*Long: đoán là bạn ấy nói về việc tiền xử lý dữ liệu) (trích Machine learning isn’t Kaggle competitions, Julia Evans). Một lý do ít hiển nhiên hơn, nhưng cũng thú vị, đó là có ý kiến cho rằng – bởi nhiều nhiều Hypotheses (*Long: bạn tạm hiểu là mô hình nhé) mà vô tình có một cái (nếu bạn may mắn) hoạt động rất hiệu quả khi test (trên hold-out set) dẫn đến việc mô hình đó ngon lành hơn các mô hình còn lại – và đương nhiên là nó lên top rồi (trích AI competitions don’t produce useful models, Luke, Oakden-Rayner, 2019).
Compute requirements: (yêu cầu về tính toán)
Ở thập kỷ vừa qua, các hệ thống ML thường siêu bự và yêu cầu tính toán ngày càng tăng cũng như dữ liệu ngày càng lớn. Theo OpenAI (*Long: nhóm này rất giỏi) thì “lượng tính toán dùng khi train một AI lớn nhất sẽ tăng gấp đôi chỉ sau 3 tháng rưỡi” (tức là sau một khoảng thời gian ngắn lại có một thằng siêu khủng ra đời, ngốn nhiều CPU, GPU.. và data hơn)
Từ AlexNet năm 2012 đến AlphaGo Zero năm 2018, năng lượng tính toán đã thằng 300 ngàn lần.
Kiến trúc tìm kiếm AmoebaNets tạo ra bởi Google AutoML team yêu cầu 450 K40 GPUs trong 7 ngày(Regularized Evolution for Image Classifier
Architecture Search, Real et al., 2018). Tức là nếu chỉ dùng 1 GPU thì nó tốn 9 năm trời.
Những mô hình khủng thì tạo ra những bài báo lý tưởng (cả khoa học lẫn báo thường), nhưng không tạo ra sản phẩm lý tưởng. Bởi chúng quá đắt để train, quá bự để nhét vào thiết bị người dùng, và quá chậm để trở nên hữu ích, Khi tôi nói chuyện với các công ty muốn dùng ML vào sản phẩm, nhiều người bảo tôi rằng họ muốn một nghiên cứu đột phá ở một Lab (phòng thí nghiệm) nào đó, và tôi phải giải thích với họ rằng mấy ông không muốn những thứ như thế đâu.
Có những giá trị không thể phủ nhận trong nghiên cứu. Những mô hình to bự kìa rồi dần dần sẽ trở nên hữu ích – khi mà cộng đồng tìm ra cách để làm chúng nhỏ lại và nhanh hơn, hoặc dùng chúng như là một mô hình gốc (pre-trained model) để tái sử dụng. Tuy nhiên, các mục đích của nghiên cứu rất khác so với production. Thế nên khi được một kỹ sư yêu cầu phát triển một hệ thống có thể dùng được trong thực tiễn, bạn phải luôn ghi nhớ mục đích của bạn là “production” (nhớ nhé).
2. Design a machine learning system
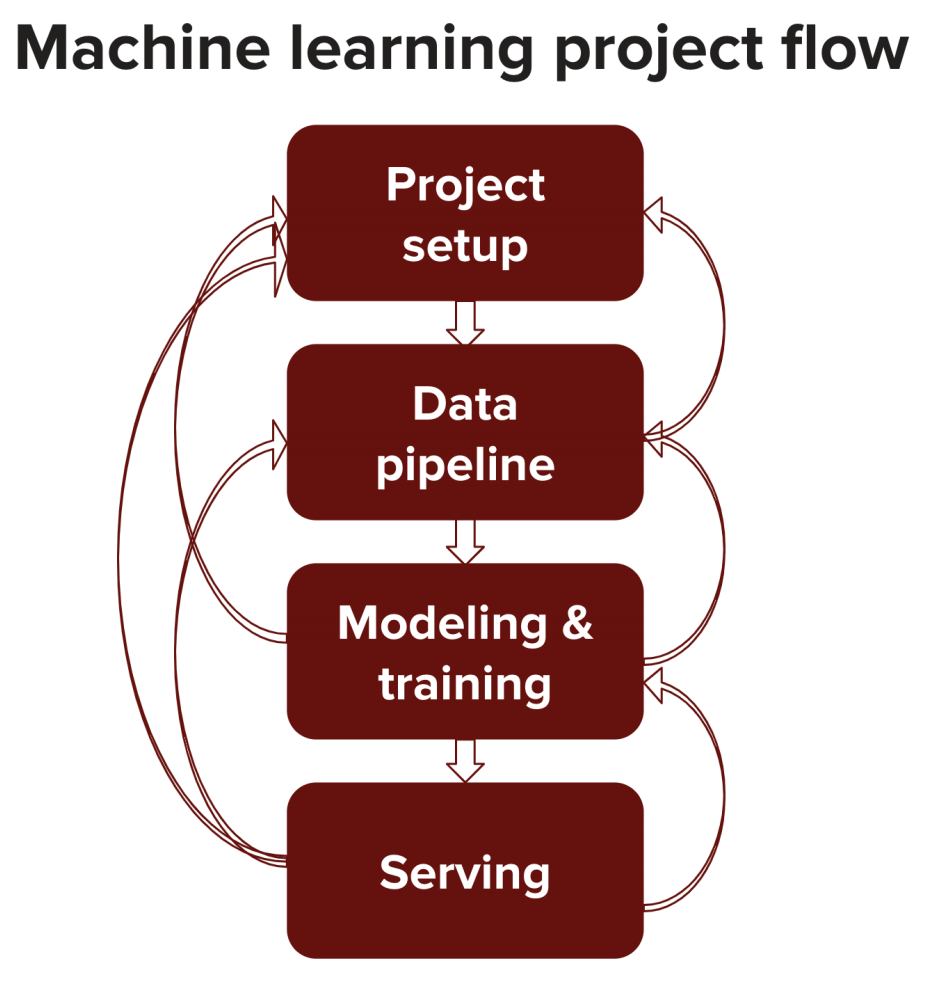
Thiết kế một hệ thống ML là một quá trình tuần tự (theo từng bước). Thông thường có 4 phần chính: project setup, data pipeline, modeling (selecting, training, and debugging your model), and serving (testing, deploying, maintaining)
(Mình để nguyên tác luôn tại nó là thuật ngữ, túm lại là có 4 phần bao gồm thiết kế dự án, pipeline – quy trình xử lý dữ liệu, tạo mô hình train/test/debug và cuối cùng là production (test, triển khai, bảo dưỡng)
Kết quả của một bước có thể sẽ được dùng để cập nhật lại các bước khác. Ví dụ:
• Sau khi kiểm tra dữ liệu đang có, thì bạn thấy rằng rất khó để có lấy được lượng dữ liệu cần thiết, thành ra bạn phải thay đổi cách tiếp cận vấn đề một chút
• Sau khi train xong, bạn thấy là phải cần nhiều dữ liệu hơn hoặc phần gán nhãn (labeling) chưa ổn lắm – cần phải làm lại bước này.
• Sau khi cho user dùng, bạn nhận ra cách mà họ sử dụng sản phẩm hoàn toàn khác với các giả định ban đầu của bạn khi train model, nên bạn phải cập nhật lại
Thế cho nên, khi được yêu cầu thiết kế một hệ thống ML, bạn phải cân nhắc cả 4 thành phần trên.
Project setup
Trước khi sờ tới “Neural Network”, bạn cần làm rõ vấn đề đang được xử lý:
• Goals (mục đích): Bạn muốn đạt được điều gì? Ví dụ, nếu bạn được yêu cầu tạo một hệ thống sắp xếp các hoạt động để đưa lên newfeeds của Facebook, một số “goals” có thể là: giảm bớt thông tin sai lệch, tối ưu doanh thu từ các nội dung được tài trợ, hoặc thu hút tương tác người dùng một cách tối đa.
•User Experience (Trải niệm người dùng): Hỏi lại nhà tuyển dụng từng bước để xem người dùng sẽ sử dụng hệ thống này như thế nào. Nếu bạn được yêu cầu phải dự đoán ứng dụng nào mà phone user sẽ dùng tiếp (ví dụ nhảy từ Facebook qua Gmail), bạn có thể muốn biết thêm những dự đoan đó được cần khi nào và như thế nào . Bạn muốn đưa ra dự đoán chỉ khi user mở khóa điện thoại của họ, hay là trong suốt quá trình họ dùng điện thoại?
• Performance constraints (Ràng buộc hiệu năng): Ứng dụng cần nhanh và chuẩn cỡ nào? Cái gì quan trọng hơn “precision” hay “recall” (*Long: wikipedia giải thích cái này khá hay nhé). Cái nào được ưu tiên hơn? giảm “false negative” hay “false positive”? Ví dụ, bạn muốn xây dựng hệ thống dự đoán liệu rằng một người có bị dị ứng với thuốc không, thế thì “false negatives” cần phải được hạn chế tối đa. Tuy nhiên, nếu bạn xây dựng dự doán “từ nào sẽ được tiếp theo khi user bấm điện thoại”, thì rõ ràng nó không cần phải quá hoàn hảo.
• Evaluation (đánh giá): Bạn đánh giá hiệu năng như thế nào trong lúc train và trong dự đoán (lúc user dùng). Khi dự đoán, thì hiệu năng hệ thống có thể bị can thiệp / ảnh hưởng bởi tương tác của người dùng. Ví dụ, có bao nhiều lần user sử dụng gợi ý của hệ thống? Nếu metric bạn dùng không thể phân biệt được, thì bạn cần một metric khác để dùng trong quá trình train, ví dụ như việc tối ưu hàm mất mát (loss function) (*Long: đoạn này hơi khó hiểu, bạn nào có ý kiến khác thì bình luận giúp mình nhé). Evaluation đôi lúc rất khó trong các mô hình sinh (generative models) – nếu bạn xây dựng một hệ thống trò chuyện, bạn sẽ đánh giá lời thoại sinh bởi hệ thống như thế nào là chuẩn?
• Personalization (cá nhân hóa): Cái mô hình của bạn nó có cần cá nhân hóa hay không? Tức là một mô hình sẽ dùng cho toàn bộ user, một nhóm users, hay là mỗi user một mô hình riêng? Nếu bạn phải dùng nhiều model, thế thì bạn có thể tạo ra một mô hình gốc (base) rồi tinh chỉnh (finetune) nó thành nhiều models để phục vụ các nhóm đối tượng khác nhau được hay không?
• Project constraints (ràng buộc của dự án): Có những ràng buộc mà bạn phải để mắt tới trong thực tiễn nhưng không phải làm thế khi phỏng vấn. Ví dụ: phải tốn bao lâu để triển khai, tốn kém về tính toán (compute – CPU) như thế nào, dự án này có những siêu nhân nào làm cùng, có những hệ thống gì sẵn có mà bạn có thể sử dụng vân vân ..
Resources (đọc thêm): Choosing the Right Metric for Evaluating Machine Learning Models by Alvira Swalin, USF-Data Science, 2018. Part I. Part II.
Data pipeline
Ở trường, bạn làm với dữ liệu sẵn có mà không mất công tìm kiếm, không bị pha tạp bởi nhiễu.. nói chung thời gian bạn dành hầu hết cho việc xây dựng và train model ML. Nhưng ra ngoài công ty, bạn sẽ cần phải dành hầu hết thời gian thu thập, đánh dấu, và làm sạch dữ liệu. Khi đi dạy, tôi hay gặp các sinh viên không ưa chuyện “data wrangling” (làm sạch dữ liệu) cho lắm vì họ cho là cái đó không có ngầu, cũng giống kiểu mấy ông backend engineer hay chê frontend không có ngầu vậy đó. Nhưng thực tế thì cái nào cũng quan trọng cả thôi.
ML bị ảnh hưởng nhiểu bởi dữ liệu thay vì thuật toán, thế nên với một thuật toán mà bạn đề ra, bạn hãy nói cho nhà tuyển dụng bạn cần bao nhiêu dữ liệu và chúng thuộc loại nào cho việc train và evaluate hệ thống của bạn.
Bạn cần phải chú ý tới input/output của hệ thống. Có nhiều cách để tiếp cận một vấn đề. Giả như với ứng dụng dự đoán bên trên, ban đầu bạn có để tiếp cận như sau: thu thập profile của user ( bao gồm age, gender, ethnicity (dân tộc), occupation (nghề), income, technical savviness (chuyên môn kỹ thuật), etc.) and và profile của môi trường (thời gian địa điểm, những app đã dùng trước đó, etc.). Biến đống đó thành input và output ra một phân phối cho từng ứng dụng (*Long: 10% sẽ dùng app A, 20% sẽ dùng app B, vân vân). Cách này hơi dở vì có quá nhiều apps và cứ mỗi khi một app được thêm vào thì bạn lại phải train lại cái model . Một cách tiếp cận tốt hơn là sử dụng input là profile của user, environment, và cái app , rồi output một kết quả của binary classification để xem nó có khớp hay không (*Long: chưa rõ lắm chỗ này, chắc giống bài nhận diện mặt của anh Andrew Ng. hehe. Việc chỉ output là có match hay không chưa đủ, mà phải là match bao nhiêu % – để từ đó rank lại xác suất các app mà user có thể sẽ mở)
Một số câu hỏi bạn có thể đề cập trong cuộc phỏng vấn:
- Data availability and collection: loại dữ liệu nào sẵn có, có nhiều cỡ nào, đã gán nhãn được bao nhiêu rồi, chất lượng gán nhãn ra sao, việc gán nhãn có tốn kém không, một mẫu cần bao nhiêu nhiều gán nhãn, xử lý bất đồng giữa các người gán nhãn ra sao, kinh phí cho việc này là chừng nào, có áp dụng được Supervised/Unsupervised learning cho việc gán nhãn tự động hay không nếu đã có sẵn một lượng nhỏ data đã được gán nhãn trước đó.
- User data: Bạn cần loại data nào từ người dùng, thu thập chung thế nào, làm sao để lấy feedback từ user, bạn muốn cải thiện hệ thống từ feedback một cách tức thời hay theo từng khoảng thời gian nhất định (ví dụ cập nhật model 1 tuần/lần)
- Storage: Lưu data ở đâu: cloud, local hay trên thiết bị người dùng. Mỗi mẫu (sample) to chừng nào, có thể nạp vào bộ nhớ được không? Cấu trúc dữ liệu nào bạn muốn dùng và có phải tradeoff (đánh đổi) gì không? Bao lâu thì data mới xuất hiện?
- Data preprocessing & representation: Bạn xử lý dữ liệu tho như thế nào, có cần feature engineering hay extraction (trích xuất) gì không? Có cần chuẩn hóa (normalization) không? Nếu thiếu data trong các mẫu thì phải làm sao? Nếu có chênh lệch giữa tỉ lệ các nhãn phải làm thế nào? Làm cách nào để đánh giá được tập train và test cùng đến từ một phân phối – và nếu không thì phải làm sao? Nếu data của bạn đến từ nhiều format text, ảnh, số thì phải kết hợp chúng như thế nào?
- Challenges: Xử lý dữ liệu người dùng cần được đặc biệt lưu ý, đã có rất nhiều công ty lớn vướng phải rắc rối với chuyện này.
- Privacy: Người dùng có những mối lo ngại nào về tính riêng tư trong dữ liệu của họ. Bạn sẽ dùng phương thức gì để ẩn danh (bảo vệ)? Bạn sẽ lưu trữ dữ liệu của họ trên server của bạn hay chỉ truy cập chúng trên thiết bị user?
- Biases: Trong data có bị biased (lệch, thiên vị một lớp dữ liệu nào đó) không? Bạn sẽ sửa chúng ra sao? Liệu việc gán nhãn của bạn đã bao gồm hết data đang có chưa? Data của bạn có củng cố thêm cái bias hiện có trong không? (*Long: đoạn này mình không thấy rõ nghĩa lắm, các bạn đọc thêm bản tiếng Anh: “Are your data and your annotation inclusive? Will your data reinforce current societal biases?”)
Resources (đọc thêm): More data usually beats better algorithms by Anand Rajaraman, Datawocky, 2008.
Modeling (mô hình hóa):
Bao gồm model selection, training, debugging. Hầu hết các khóa học đều có mấy thứ này, tuy nhiên đây chỉ là một phần nhỏ của cả quá trình nãy giờ chúng ta tìm hiểu. Nhiều người còn cho rằng đây là phần dễ nhất (*Long: có thể là như vậy thật..)

Model Selection: lựa chọn mô hình
Hầu hết các vấn đề đều có thể được tiếp cận bằng một trong số mấy thuật toán phổ biến, thế cho nên bạn biết các nhiều chức năng của mỗi loại thì sẽ càng có ích. Đầu tiên, hãy xem phạm trù của vấn đề nó nằm ở đâu: đây là supervised hay unsupervised learning? Regression (hồi quy) hay Classification (phân loại)? Bài toán có yêu cầu model sinh (generation) ra output (ví dụ 1 ảnh) không hay chỉ dự đoán (prediction) mà thôi?
Trong generation, mô hình phải học mối tương quan giữa data, và cái này khó hơn nhiều là chỉ prediction.
Cũng phải nói thêm là cái đống bên trên nó không tách bạch với nhau, tức là 1 task dự đoán có thể dùng regression nếu bạn dữ đoán một giá trị, nhưng cần dùng classification khi chúng ta muốn đưa con số đó vào một category (phạm trù) nào đấy. Tương tự, bạn có thể dùng unsupervised learning để gán nhãn, và dùng supervised để học mấy nhãn đó. Rồi thì bạn có thể chuyển câu hỏi thành từng task: object recognition (nhận diện đối tượng), phân loại text, time series analysis (phân tích chuỗi thời gian), hệ thống góp ý, dimensionality reduction (giảm chiều/độ phức tạp của dữ liệu). Luôn nhớ là có nhiều hơn một cách để tiếp cận vấn đề, bạn sẽ không biết được cách nào ngon hơn cho tới khi bạn train/test thử.
Khi tìm kiếm giải pháp, tránh sử dụng những thuật ngữ mơ hồ và showoff kiên thức, mà hãy tập trung vào giải pháp đơn giản nhưng hiệu quả. Thứ nhất nó giúp bạn debug dễ dàng hơn khi thêm thắt từng phần code, thứ hai là nó giúp bạn so sánh cái baseline của model đơn giản với những mô hình phức tạp.
Thiết lập một baseline hợp lý là điều quan trọng nhưng các ứng viên lại hay bỏ sót. Có 3 dạng baseline bạn cần để ý như sau:
• Random baseline: baseline ngẫu nhiên chỉ ra rằng nếu bạn phải dự đoán mọi thứ một cách ngẫu nhiên thì hiệu quả mong đợi là bao nhiệu.
• Human baseline: nếu con người thực hiện task này thì như thế nào?
• Simple heuristic: ví dụ một task như sau: gợi ý cho bạn ứng dụng tiếp theo mà bạn sẽ mở lên trên điện thoại, thế thì mô hình căn bản nhất là dựa vào tần suất bạn sử dụng các ứng dụng, sắp xếp chúng, và đưa ra gợi ý. Nếu cách tiếp cận này có thể dự đoán đúng được tầm 70% thì các mô hình mà bạn xây dựng có được hiệu suất tốt hơn phải đảm bảo là chúng không quá tốn kém (độ phức tạp, hay thời gian lý).
Your first step to approaching any problem is to find its effective heuristics. Martin Zinkevich, a
research scientist at Google, explained in his handbook Rules of Machine Learning: Best
Practices for ML Engineering that “if you think that machine learning will give you a 100%
boost, then a heuristic will get you 50% of the way there.” However, resist the trap of
increasingly complex heuristics. If your system has more than 100 nested if-else, it’s time to
switch to machine learning.
When considering machine learning models, don’t forget that non-deep learning models exist.
Deep learning models are often expensive to train and hard to explain. Most of the time, in
production, they are only useful if their performance is unquestionably superior. For example,
for the task of classification, before using a transformer-based model with 300 million
parameters, see if a decision tree works. For fraud detection, before wielding complex neural
networks, try one of the many popular non-neural network approaches such as k-nearest
neighbor classifier.
Most real world problems might not even need deep learning. Deep learning needs data, and
to gather data, you might first need users. To avoid the catch-22, you might want to launch
your product without deep learning to gather user data to train your system.
Resources:
• Machine Learning Algorithms: Which One to Choose for Your Problem by Daniil Korbut, Stats and Bots, 2017.